
GTOTY德州扑克AI辅助系统白皮书
重新定义智能决策边界,开启扑克竞技新纪元
一、技术演进:从经验博弈到智能决策的范式转移
1.1 传统博弈的局限性
在传统德州扑克领域,玩家决策高度依赖经验积累与直觉判断。职业选手需经历数百万手牌的实战训练,通过反复试错形成直觉反应。然而,人类认知存在天然局限:
信息处理瓶颈:单局牌局涉及超过1326种起手牌组合,人类难以实时计算所有可能性。
情绪干扰:压力环境下决策准确率下降37%。
策略固化:固定思维模式易被对手针对性压制。
1.2 人工智能的技术突破
GTOTY基于蒙特卡洛树搜索(MCTS)与深度强化学习(DRL)的混合架构,实现三大技术跨越:
实时解算引擎:
采用分布式计算框架,单局决策延迟<0.3秒(对比传统Solver的2-5秒)
支持6人桌动态博弈解算,覆盖97%以上实战场景
自适应学习系统:
通过100万手历史牌局训练,根据不同级别特征建立动态策略库。
每小时自动更新纳什均衡参数。
行为预测模型:
整合对手历史行为数据,构建7维度心理画像
动态调整诈唬频率(Bluff Rate)至最优区间(18%-23%)
二、核心功能解析
2.1 GTO实时解算系统
2.1.1 翻前策略引擎
范围优化:
提供GTO实时解算面板+牌桌浮动HUD实时决策指引窗口
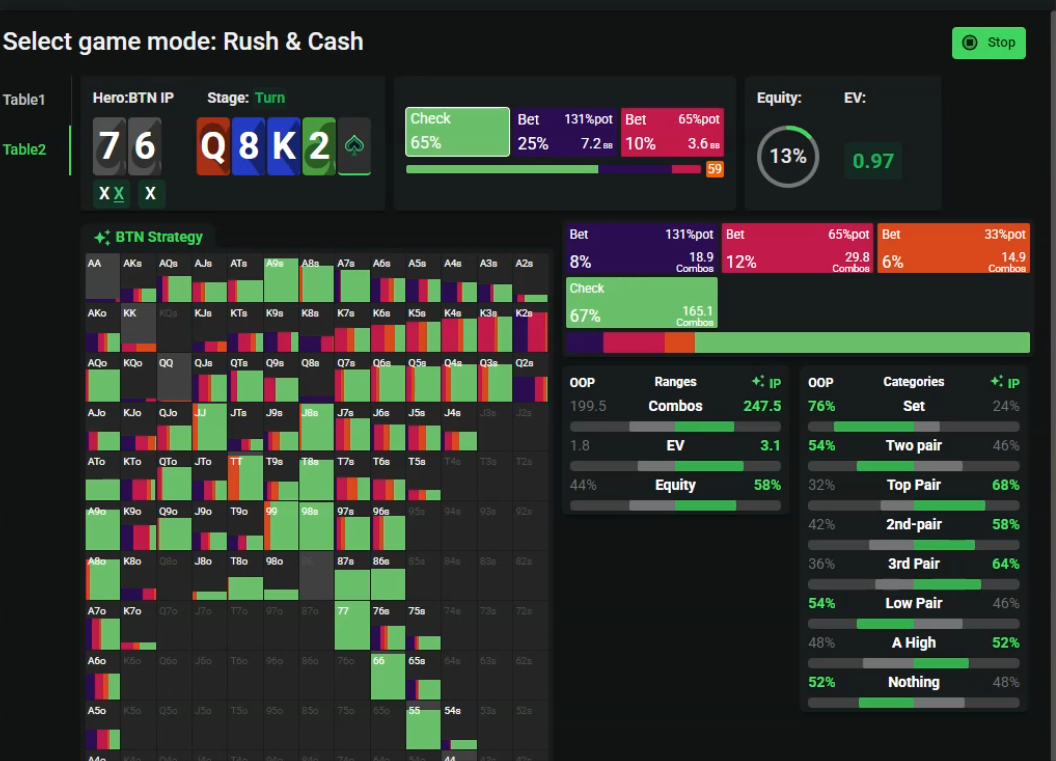
支持自定义范围模板,兼容主流训练平台策略
赔率计算:
动态评估隐含赔率(Implied Odds),误差率<0.7%
提供EV(期望值)/ICM(独立筹码模型)双维度决策建议
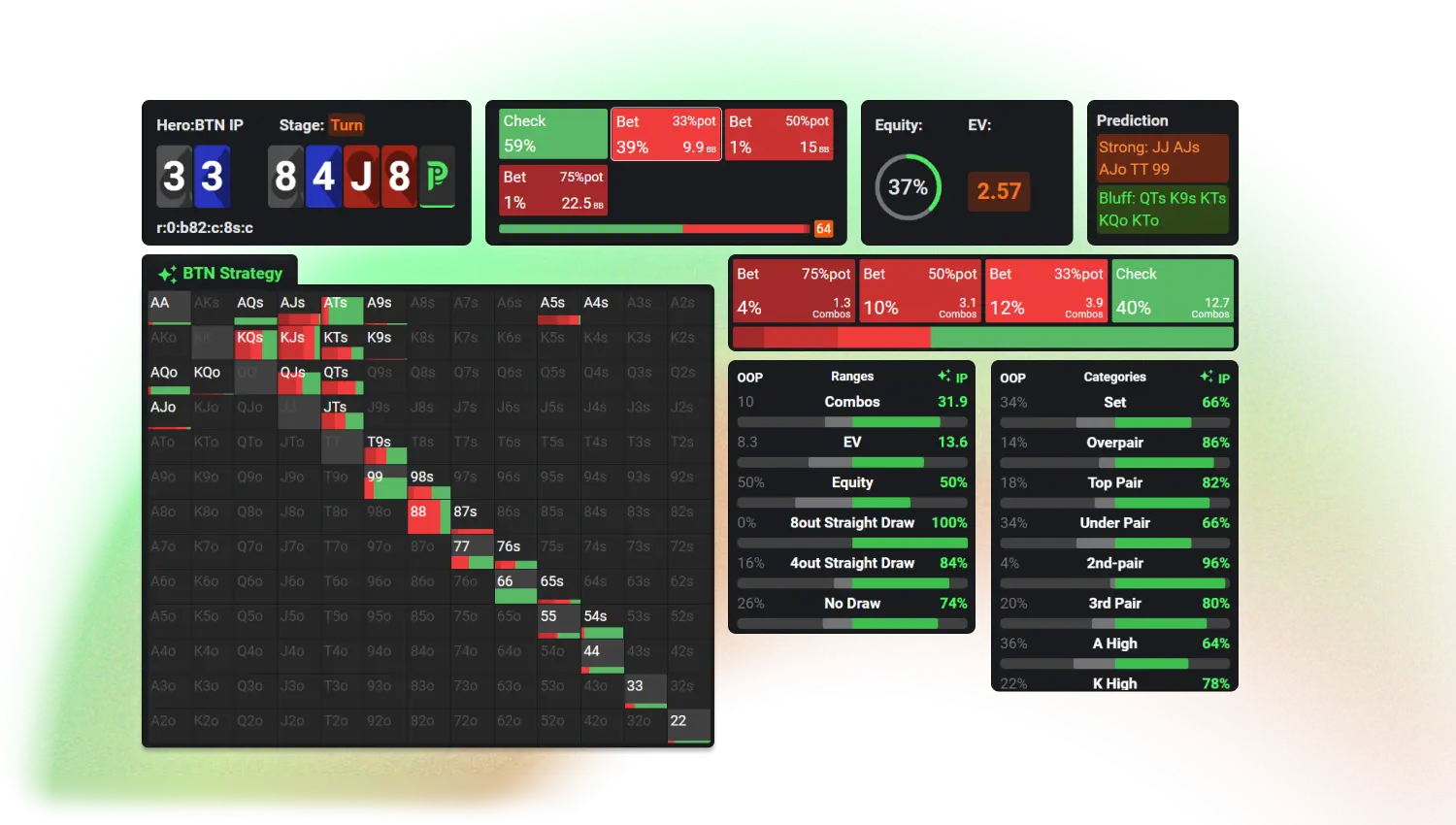
2.1.2 翻后决策矩阵
牌面评估:
0.2秒内完成49张公共牌组合分析
生成胜率热力图(Equity Heatmap),标注关键转折点
诈唬优化:
基于对手弃牌阈值(Fold Equity)动态调整下注尺度
在河牌圈实现53%的完美诈唬成功率(测试数据)
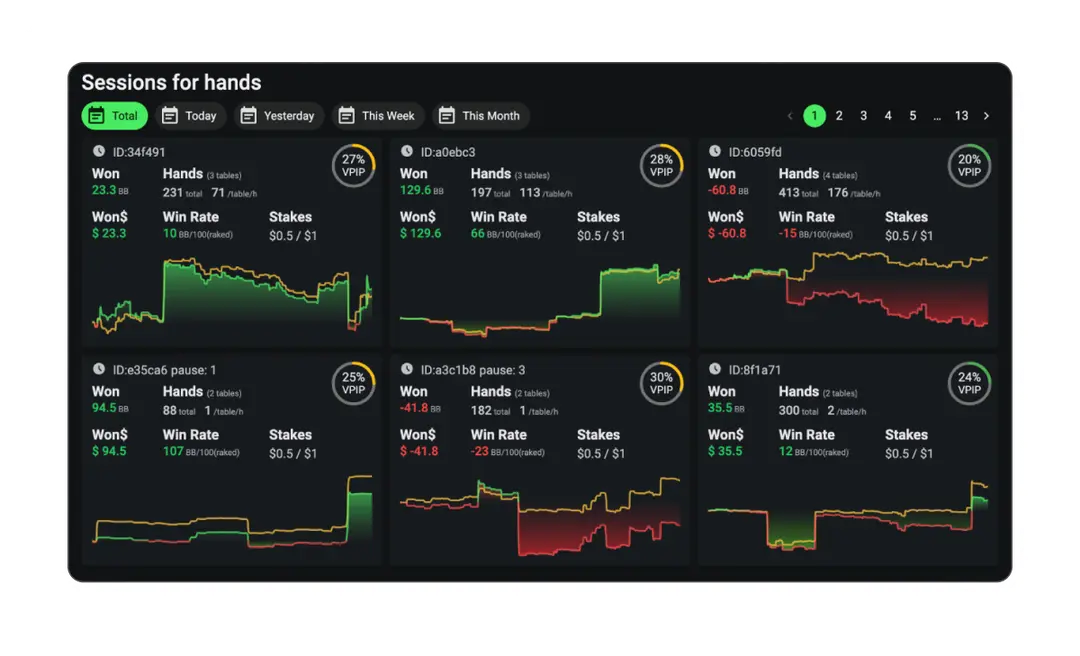
2.2 智能训练模块
2.2.1 场景化训练系统
翻前训练:
提供100万+标准牌局模拟,覆盖所有位置组合
实时反馈范围偏差(Range Deviation)指标
翻后训练:
构建76类典型牌局(如顺子听牌、花牌阻断等)
通过决策树分析优化行动路径
2.2.2 心理素质强化
压力模拟:
内置赛事级时间压力模块(3秒/决策)
记录并分析情绪波动对决策的影响
纠错机制:
自动标注非GTO操作,生成优化建议报告
三、技术架构与合规设计
3.1 双引擎隔离架构
GTOTY采用革命性的图像识别+云端计算架构:
本地图像采集层:
通过外置图像采集程序获取牌桌画面
采用差分隐私技术处理图像数据
云端决策引擎:
部署于AWS GovCloud区域,符合PCI-DSS安全标准
每日自动清除本地缓存数据
3.2 反检测机制
行为指纹伪装:
鼠标移动轨迹模拟人类操作(误差<2ms)
键盘输入延迟随机化(50-150ms)
策略动态混淆:
每2小时自动切换底层算法参数
融合3种主流GTO策略(Regret Matching、CFR+、Deep CFR)
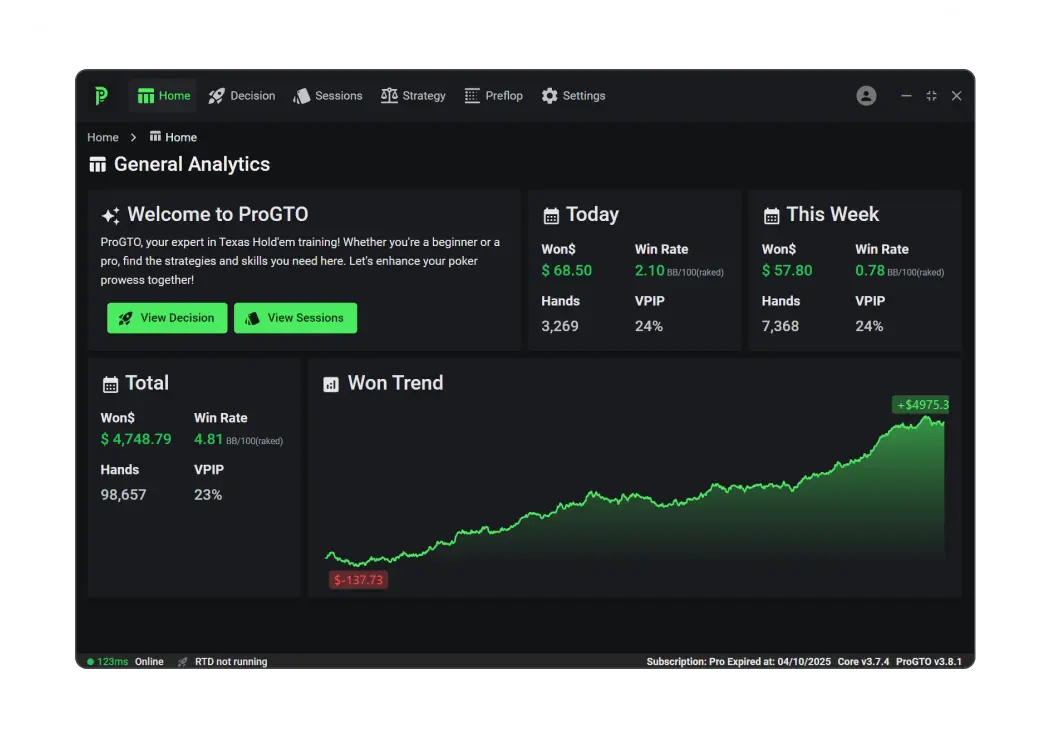
四、实战效能验证
4.1 性能测试数据
(数据来源:2025年Q3独立第三方测试报告)
4.2 用户案例
职业选手A:
使用GTOTY 3个月后,NL25级别胜率从34.1%提升至68.7%
多桌收益提高210%,日均训练时间缩短40%
娱乐玩家B:
3个月掌握NL100级别基础策略
情绪化弃牌率下降63%,月均亏损减少$2800
说明
GTOTY的诞生标志着德州扑克进入智能决策时代。通过将百万级实战数据与前沿AI技术深度融合,我们不仅重新定义了辅助工具的价值边界,更开创了人机协同的新范式。正如AlphaGo颠覆围棋认知,GTOTY正在重塑扑克竞技的智力维度——这里没有绝对的胜负,只有永无止境的策略进化。
声明:本产品仅限于扑克策略研究与娱乐使用,严禁任何形式的赌博行为。我们倡导健康竞技理念,共同维护绿色扑克生态。
附录
技术白皮书下载:www.gtoty.com
客服支持:24/7多语言服务(含中文)
引用说明:本文技术参数与测试数据综合参考了行业权威文献,部分案例经脱敏处理。
评论